Hello @all, we’ve got something new to share for testing, currently via a cookie. I’ll explain the functionality first, then put the method for how to try it out.
What this is
This functionality is a first version of a blog search, with the intention being that we’ll eventually incorporate a whole range of different writers across many platforms into this separate tab. Much like /news pulls together news sources, this would allow for a search just across a range of different independent writers, bloggers etc.
For the moment, due to the ease of implementing it as a v1, this only incorporates Substack. The range of options in this one website, ease of adding in feeds, and coverage we already had in the index, made it a simple one to rig up.
This intention of broadening out the search is why it has been given /blogs to sit on.
How to test it out
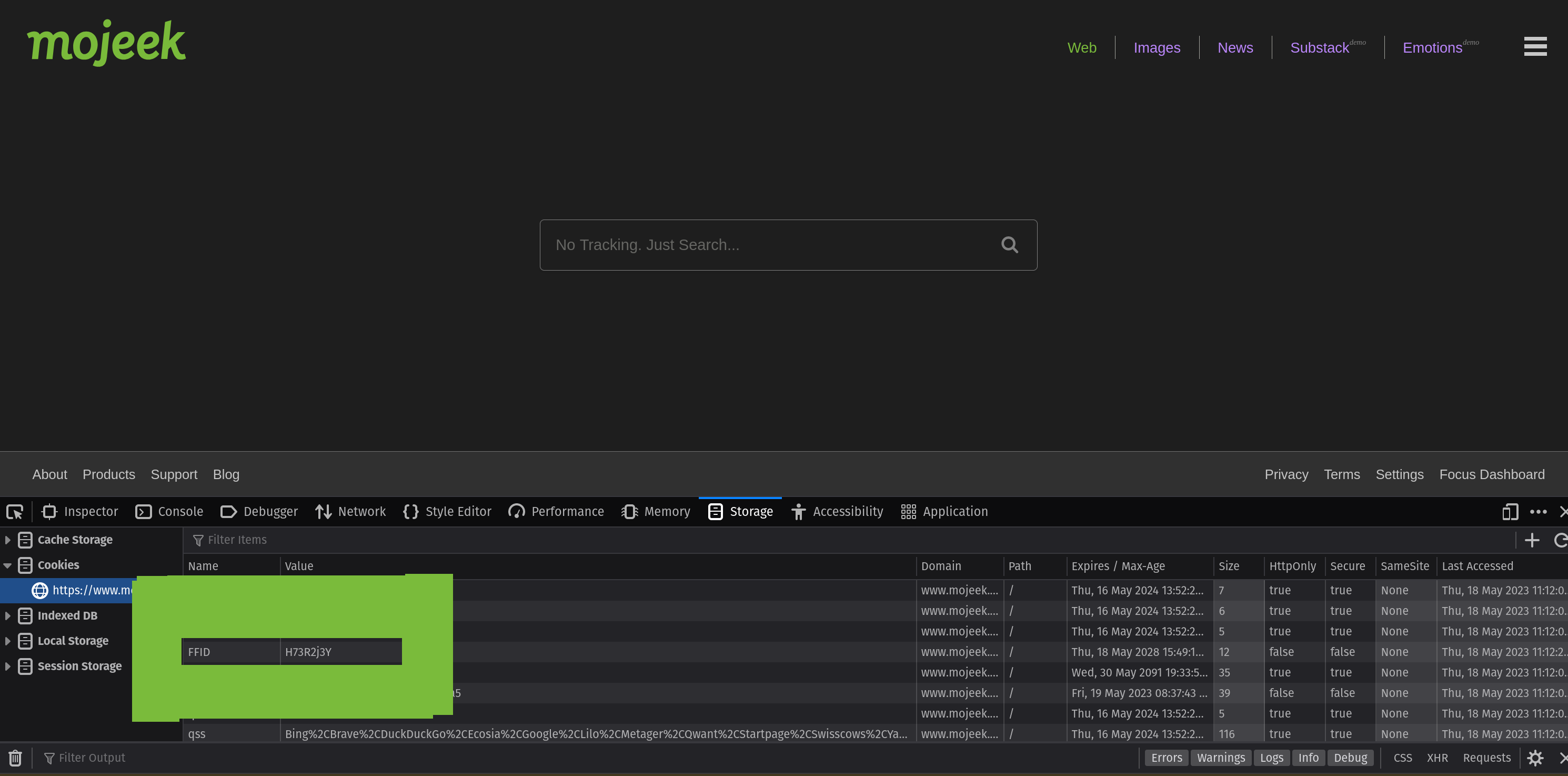
Much like with Focus, you can access this functionality with an FFID cookie using the value H73R2j3Y on path / like so:
This is a great idea for a feature! I’m often on the lookout for new and interesting (or old and venerable) blogs. I’ll have to think of some topics to search for later, but from my first attempt, I didn’t get any Substack results: https://www.mojeek.com/search?q=search+engines&fmt=sst&sst=1
It definitely counts as something to investigate, as that is just regular search results. Are you okay with giving me your cookieless link so we can see if there’s something pushing or pulling it away from working as expected? DM is all good if so
Oh of course, sorry, assumptions; in Search Settings - Mojeek on the right there is a box which populates with a link you can use instead of saving settings in a cookie, it’s a quick way also of being able to see what has been set by someone, and then from there check if anything is affecting anything else.
This being said, if it works now, all good to leave it unless this happens again.
Ah yes, I understand now. I knew I’d heard that term before.
Here’s mine if it’s useful to you: https://www.mojeek.com/?theme=light&t=40&tn=5&date=1&cdate=1&si=3&autocomp=0
Tangentially, I think the cookieless link would be much more useful to users if you served a different OpenSearch document depending on what query parameters appear in the URL. That way, users could set Mojeek as the default search engine, and it will always have particular settings without setting cookies.
This is most useful for desktop Firefox users, because Chromium-based browsers allow you to edit the search engine link directly, while Firefox doesn’t (except in obscure ways). One has to wonder what the point of an open standard is if every browser handles it differently, and not even consistently across platforms…
Interesting feature! I like. Hopefully you can add more sources soon.
Differentiation between blogs and other sites
How are you planning to differentiate between blogs, news sites and just other websites (like corporate etc.)? If you’re talking about blogs, I think about WordPress (professional malformation). But there are many different types of websites using WordPress. So I’m curious as to how you’ll distinguish blogs from other sites?
Feeds
Another idea from here: Are you using RSS feeds for this? If so, then perhaps you could make that available as well (with a link or an icon next to the search results)? This way, a user can easily subscribe to that feed with an RSS reader. Or you could cater to the wishes to see the entire feed (with a link or button to a page with all articles of the feed in chronological, or user definable, order)?
Currently an open question; it will likely keep to independents as much as possible. Whereas /news has larger organisations/media, this would probably pull together smaller outlets and individual writers.
Part and part, Substack here is being used as the additions are all quite easy (they all have feeds at /feed) and because of the number of independent writers on it, but also because our index already covers Substack pretty well - there are RSS feeds in this tool as well.
Regarding heuristics to detect blogs, here are some positive signals:
Website technology fingerprinting. There are tons and tons of open-source OSINT tools to do this, for reference. If you detect that a website uses, say, Ghost or Blogger, you can increase its “probably a blog” score.
Feed detection. Websites with RSS/Atom/WebSub/JSON feeds are more likely to be blogs.
Open Graph “article” metadata.
schema.org metadata indicating a “BlogPosting” or “Article” type. Blogger uses Microdata syntax for this; WordPress often uses JSON-LD.
Whether it triggers “reader mode” heuristics in a reader mode implementation. Readability and DOM-Distiller have several open-source implementations in multiple programming languages.
Existing directories. Search My Site and Brave’s “tech blogs” goggle are two public directories of blogs used by blog-focused search engines, which you could use as a starting point.
The best engine in this space is Marginalia. It might be worth reaching out to see if Viktor wants to share.
Thanks for these, for the moment we’re looking for feedback on the functionality as it stands, so all and any would be appreciated, including anything that looks off
FWIW; like 80% of the secret sauce for Marginalia Search’s ability is in the ranking algorithm, which basically sticks explore2.marginalia.nu’s data set into personalized pagerank and seeds it with a small curated list of websites with nice vibes.
I’ve added fingerprinting very recently and it works really well too, especially in combination with requiring few script tags and a high ratio of text to markup.
If you do a Marginalia search for like ‘generator:hugo q<2’ you get almost entirely blogs. Even if you set the filter to ‘no ranking’ and add ‘rank>200’ to neuter the effect of the ranking algorithm, precision is very high. This can be contrasted with ‘js:true q<2 rank<20’ which is just some-but-low-js websites with a low rank; both have a very indie vibe but the latter is mostly due to the ranking algorithm.
Everyone seems to use microformats, opengraph and other semantic formats these days; it appears to be included in popular SEO guides so it’s like fleas on a stray dog. Hasn’t proven super good at differentiating blogs from commercial websites. If anything, the best quality heuristic I’ve found is noncompliance with popular SEO advice.
I’d distinguish typical SEO advice from basic search-engine compatibility. Lots of people with static site generators use templates that offer structured data. I wouldn’t penalize use of semantic markup if the site seems hand-made: it being generated by a static-site generator, lacking JavaScript, or having less-common vocabulary (i.e. something besides schema.org or ogp.me) could be possible indicators, as well as having an unusual fingerprint.
Full disclosure: I’m hella biased, as my own website heavily uses Microdata and Microformats but is statically-generated with Hugo, with my own templates.