It seems like I end up talking about Kagi often these days, but they do something like this:
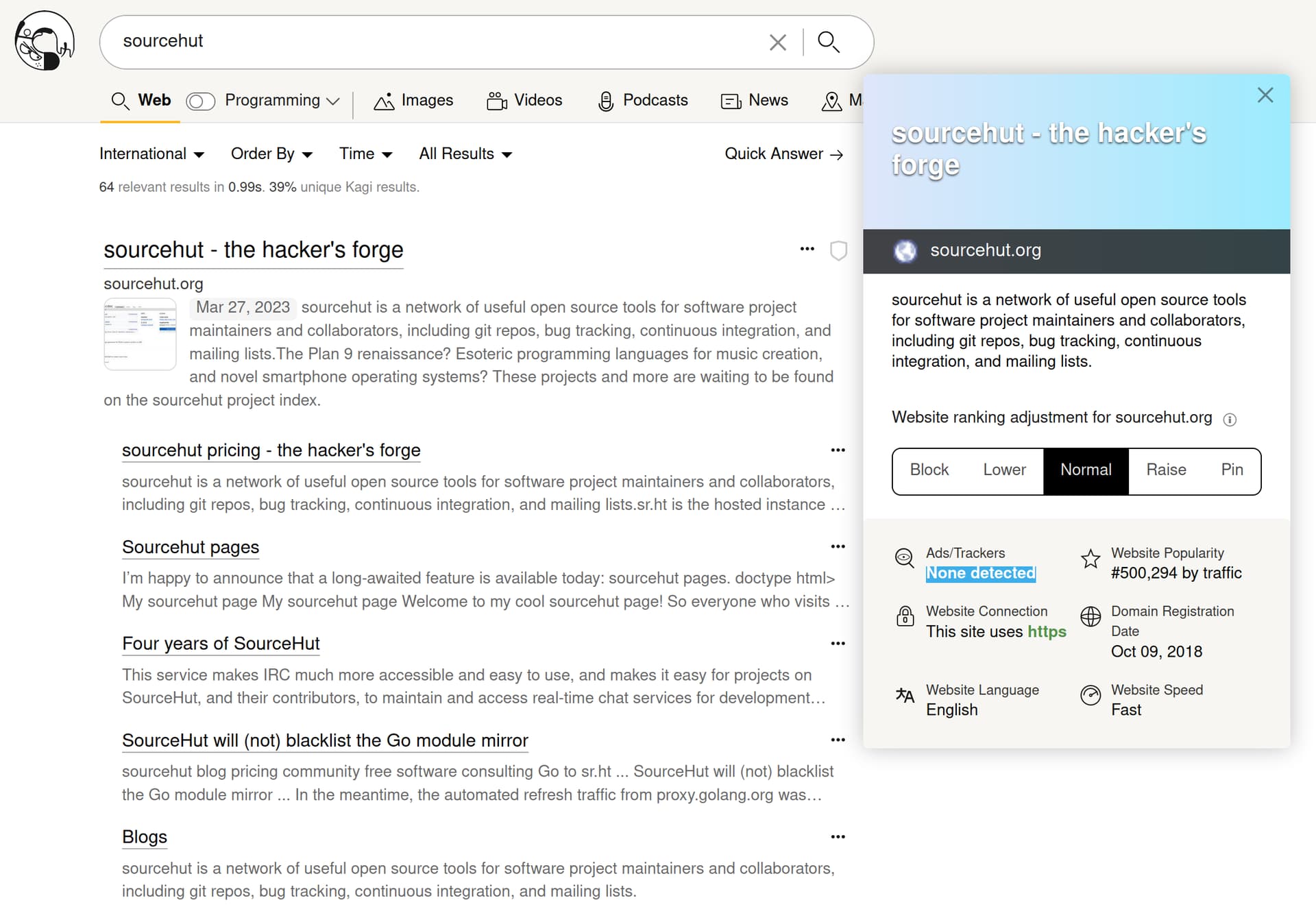
They don’t allow you to sort by trackers, though might one day: Downweigh domains in search results based on amount of ads/trackers - Kagi Feedback
It just tells you how many trackers there are for the result. You can try using their non-commercial lens to narrow it down to sites with less than 5 trackers. One of their indexes, Teclis, only indexes sites with fewer than 5 trackers/ads, under a certain level of popularity.
It’s worth pointing out that Kagi uses Bing and Google for most of their results, among other indexes, so every search is indirectly funding Bing and Google via their API. They almost certainly make more money per every Kagi search than every user who searches Bing/Google and sees a few ads. And Bing’s API prices keep going up: Microsoft Significantly Increases Bing API Search Pricing
So I really like Kagi for its user experience but don’t like the way it heavily relies on tech giants, which is why my default search engine remains Mojeek. Also, I don’t like needing to worry about my search consumption 