I highly appreciate the existence of private search engines, such as DuckDuckGo (the most popular one) and of course Mojeek, as well as many others. However, something that leaves me a bit dumbfounded is… what’s the point of having a private search engine when the search, while private, gives non-private results? I’ll try to explain better.
Many (I would say most, in fact) of the results that one has while searching with a private search engine are websites that have some form of tracking in it. For example Doubleclick, Google Analytics, Facebook Pixel, and so on and so on (there is a huge amount of those). I have Brave Browser, so I see those trackers and their names. On my laptop I have a text file where I keep the URL’s of the webpages where Brave Browser does not detect any form of tracking. However, this process is time-consuming and it’s mostly luck-related. Sure, there are quite a lot of pages with no tracking, but they are a minority compared to the results one may find.
I was wondering, since Mojeek has a forum where I can give feedback, would it be possible to have a search option that ONLY gives results of websites where no trackers are detected? I think that would be great. If it’s not possible, fine, I guess I was just hoping too much, lol.
hi @Someone666 - i’ll be interested to hear what mojeek staff has to say about your request but i suspect that fulfilling it would not be viable
i think the better way to handle this would be to use a privacy respecting browser that eliminated tracking… if any existed… which, technically, there aren’t any
Brave is a start, though i’m not familiar with it or its anti-tracking/anti-fingerprinting capabilities out-of-the-box
in short, all modern web browsers suck because they have to since the modern web sucks and the browser has to deal with it
that said, i personally recommend Firefox for a few key reasons: 1) it sucks somewhat less than other mainstream browsers, 2) Mozilla is continuing support (for now) for add-on manifest v2 (important for ad-blockers), 3) it’s highly configurable, 4) the fine and very knowledgeable folks running the arkenfox project have already done much of the work for you
Well… for me it’s not JUST about eliminating tracking. Brave Browser (supposedly) blocks those trackers whose names I see. For me it’s also something a bit more “symbolic” (I’m not sure how to explain). I would like to browse the part of the web that is not “contaminated” (for a lack of a better word) by those trackers. I often find that those websites look “cleaner” and their content is often more interesting (IMHO). Even if the trackers are blocked, the websites that have trackers still function according to the “data business” logic. I’m not good at explaining this, sorry, lol. I would like to find websites that do not have trackers in the first place, for many additional reasons other than the fact I do not want to be tracked.
I know pretty much nothing about how search engines work. I wonder if the crawler can somehow detect the presence of those trackers, and then, if that option I’m thinking of is turned on, then those websites are simply not delivered in the search results. I’m a bit afraid that is not possible, but I want to find out the truth instead of just assuming things so that’s why I’m asking here.
this is probably not the solution you’re looking for, but i thought it might interest you - there are search engines that cater to personal websites and older websites - for example Wiby
funny, i thought i read something about Mojeek doing a similar thing but i couldn’t quickly figure out if that was implemented
Thank you for letting me know about Wiby! It’s not what I was looking for (in fact, some of those websites do have trackers, like Doubleclick… and probably not every website that does not have trackers will show up in the searches… and that’s not the goal of Wiby either) but it’s pretty nice! I hope someone who works at Mojeek will reply here and say whether or not a feature like the one I’m imagining could be implemented. I don’t know anything about how search engines work, but I hope such feature can be done.
It just tells you how many trackers there are for the result. You can try using their non-commercial lens to narrow it down to sites with less than 5 trackers. One of their indexes, Teclis, only indexes sites with fewer than 5 trackers/ads, under a certain level of popularity.
It’s worth pointing out that Kagi uses Bing and Google for most of their results, among other indexes, so every search is indirectly funding Bing and Google via their API. They almost certainly make more money per every Kagi search than every user who searches Bing/Google and sees a few ads. And Bing’s API prices keep going up: Microsoft Significantly Increases Bing API Search Pricing
So I really like Kagi for its user experience but don’t like the way it heavily relies on tech giants, which is why my default search engine remains Mojeek. Also, I don’t like needing to worry about my search consumption
This is a good idea, and something that we’ve looked into before. Although not currently a priority we do have some ideas about how similar functionality could be provided.
The main issue when it comes to things like this is that whatever we put in to detect and categorise pages for this, it would have to work its way through the index. This means if we started today, it wouldn’t be available in a functional way for a while. It’s likely/sketched plans are to gradually add in bits until we get to somewhere where it could be offered up. It’s more about the crawl than attempting to judge from the index as is, if that makes sense.
Also, my manners welcome @Someone666, it’s good to have you here
I know about Kagi, especially because it’s where I get redirected when I type the Peekier URL. Peekier does not exist anymore, unfortunately, and it redirects to Kagi, which is a paid search engine.
And thank you, Josh! I hope one day that is a feature that can be implemented! I think it would be awesome!
I found what I was searching for (though it filters out pages with Javascript rather than pages with trackers… but pages without Javascript always have no tracking)
“Deny JS”
Beautiful. Welcome to the clean Internet
(P.S. I hope Mojeek can do this as well in the future, it’s always nice to have more than one search engine to have a feature like this
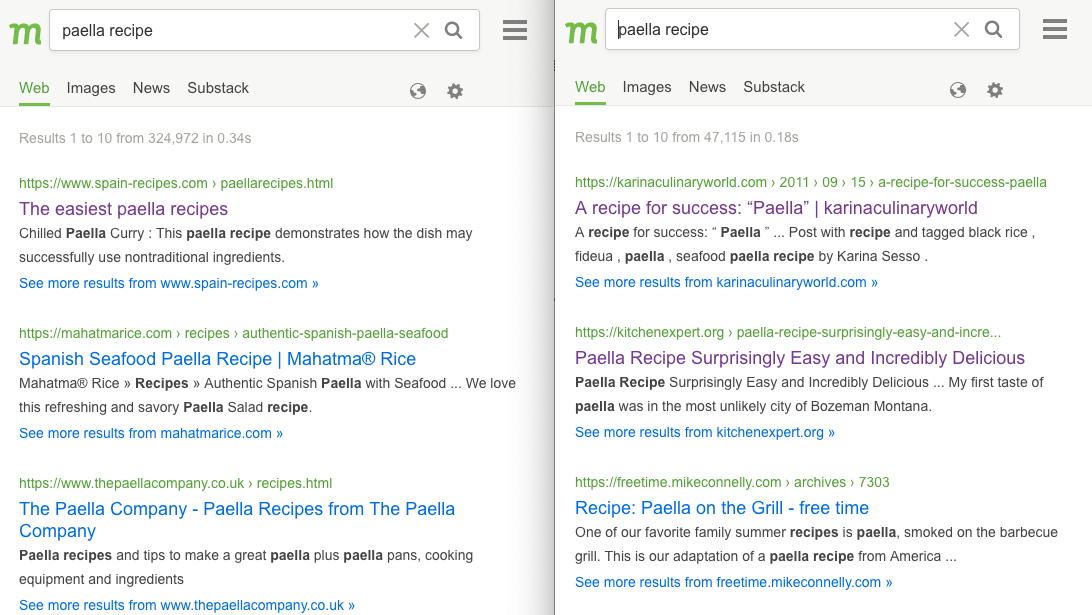
You will be pleased to learn we have been working on just this. We now have a parameter to exclude pages with javascript; &nojr=1. This will not work 100% yet; it is working itself through the index but you can use it now.
Hi Colin, that’s great to know! I have tried adding that parameter to the URL but unfortunately it does not seem to work. The results are indeed different (and less quantity) but they do contain Javascript and trackers. I hope in the future it will actually work. Thank you very much Colin and Mojeek developers in general for working on this, anyway! ^^
I’ve also experienced the same with my queries, but I can say that kitchenexpert.org is a fast site with reasonable image sizes, which is so unusual for recipe sites. Though, unfortunately, they don’t load without Javascript enabled probably due to a CSS property (although you can also use Reader mode to see them).
Hey @Someone666, the parameter in question njor=1 is just to exclude JavaScript, not trackers. It will not work 100% yet, as you’ve found, as it is working its way through the index.
Yes, Josh, I know that the parameter is to exclude Javascript. However, as far as I’m aware of, pages wihout Javascript also do not contain trackers (though pages with Javacript do not necessarily contain trackers). I can see the parameter is working itself through the index, because the number of results for that specific query that is put in the example has been decreasing gradually. When Colin posted that example “paella recipe”, the results were 47,115 whereas right now they are 46,542. I suspect that is the indication that it is indeed working itself through the index. However, the results still seem to contain Javascript, and that means the parameter still has not finished working itself through the index. I wonder how long it will take. Maybe a few months? Less? Thank you very much Mojeek development team for this, anyway, I appreciate it a lot
By and large, but I’m just restating here that the functionality is pitched as JS exclusion, not tracker exclusion.
We are nearly there but it is hard to say when we’d reach a final point. We can see that it is working correctly but it has to remove these pages from the “index”, so the final point will be reached upon a repeated recrawl of everything thankfully this is all happening in the background regardless.
As long as I’ll see “Karina Culinary World” and “Kitchen Experts” in the search results of that query, I’ll know it hasn’t finished working through the index yet