Since the beginning of July, Twitter has required users to log in to see profiles. For example, it is no longer possible to see the local weather tweets.
My question is, how has this impacted Mojeek’s web crawler? And, if there is a problem then are there any options to restore access or performance?
It seems that, like Facebook and TikTok, Twitter has now cut off a massive part of the Internet from public view: creating another proprietary silo and further fracturing the open Web.
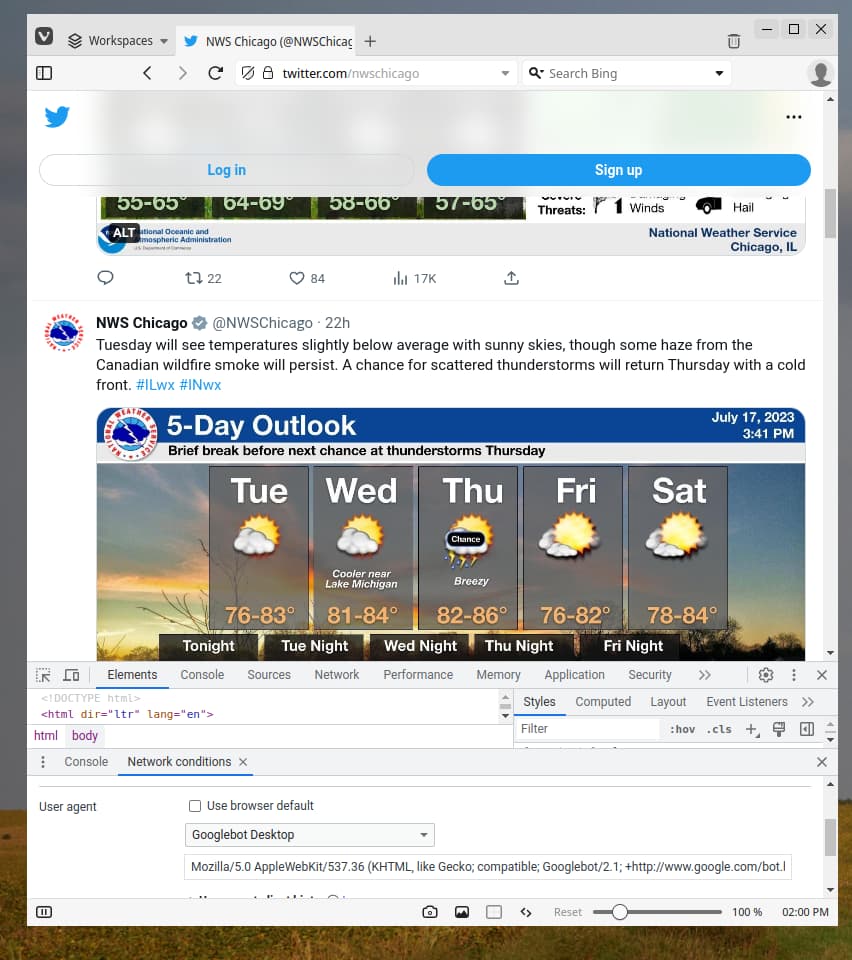
Looking into it further we are able to crawl; there is no issue with the page that you’ve suggested and I’m able to pick up Tweets which come from July 2023.
I noticed that changing the user agent to a bot isn’t the perfect solution. After 3 profiles, accessing a 4th profile results in a message “This page is not available”. So you are limited to the amount of profiles you can see this way. A hashtag ‘overview’ page doesn’t load any tweets (even though he page itself loads) and replies to separate tweets also don’t load.
Elon Musk was going to limit bots on Twitter. He wanted to decrease the number of bot accounts and prevent Twitter content being used to train LLM’s. I guess that search engine crawlers are also affected by those measures.