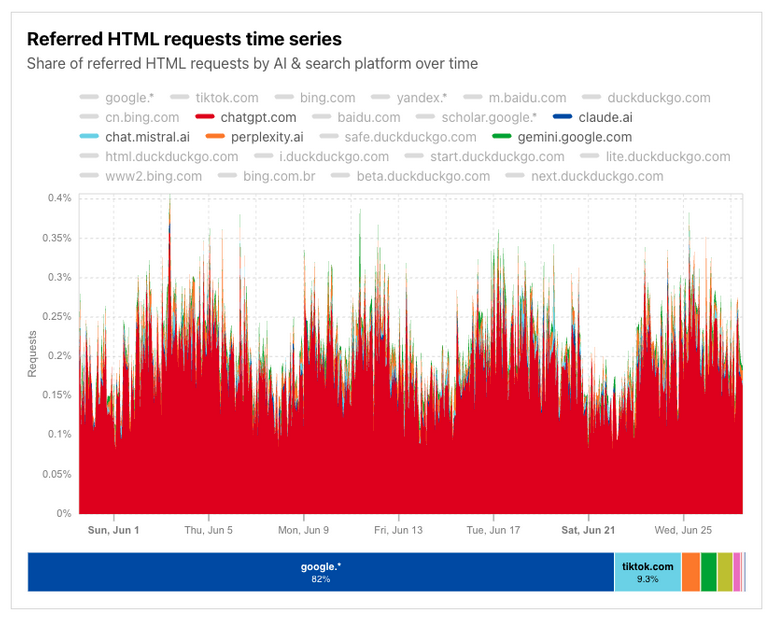
Cloudflare have provided stats on a metric for what they call crawl-to-refer ratio; how often a given a platform sends traffic to a site relative to how often it crawls that site. They include a graph, shown below, showing that traffic referred from AI products is ~0.2% of that from search+AI platforms.
Tragedy of the commons? The current state of play there is little incentive for people to contribute to the web given those ratios. Maybe not so much the commons, but the big tech gatekeepers making it that way.
I made a biology education website when I left school and I think it has received a few thousand years of reading time. Nowadays it’d be a tiny fraction of that, though in fairness it ran ads and paid for itself. That’s the problem nowadays, it doesn’t pay to write unique content.
The average person is essentially lazy and will click on the first link in the AI summary. They will not dig deeper.
It will take some time for pushback to form against AI search but it will happen as webmasters see their websites getting hammered by AI bots but getting little or no traffic in return.
Me, I want my 10 links for a search query, and I never want to see AI or AI summaries. Ever.
@Brad I wonder if new information will also dry up for the AIs to learn given the poor ratio. I hope most webmasters feel inclined to block the AI bots.
I’d like to see that but maybe it’s wishful thinking- given that entire sites will be scraped/mirrored and not have the blocks intact, as well as third party scraping and non-obvious user agents etc.
I like the idea of a new DMOZ with some help from AI to categorise and admin like checking for dead/changed pages but with some sort of semi verified humans doing the rating/algo. There’s a page or two I can think of that would cover my local town for instance, but could probably be improved.
Likely the site becomes a target for automated spam as well as whatever agents hitting it.
I got my first referral on a website I host from ChatGPT last month. And it was for something I’d written less than a year ago. So my website is definitely being actively scraped…and I wonder how many people are getting information from my website without clicking on it.
I don’t get anything from the site; I don’t run ads or make any money from it. But it still bugs me to see something I spent hours writing end up in a response from a chatbot developed by a company that expends billions of dollars a year. Maybe they could spend a little money training their data harvesting client to read robots.txt? Blocking it there doesn’t seem to have made a difference.
I guess I’m glad at least one person actually clicked on the link. I wonder how many didn’t. Pay-per-crawl is a nice idea. I hope it doesn’t make crawling harder for real search engines like Mojeek.